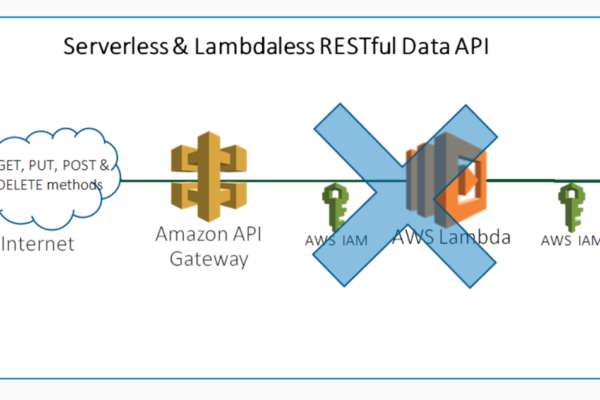
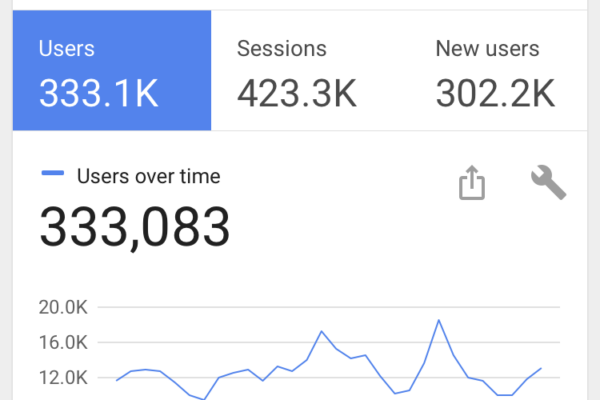
Site Reliability Engineering (SRE) is a discipline that combines aspects of software engineering and applies them to operations whose goal is to create scalable and reliable software systems. SRE teams are responsible for the reliability, performance, scalability, and monitoring of software systems. The SRE culture originated in the early 2000s […]
Read More